Julien Delange • Wednesday, June 29, 2022

AUTHOR
JD
Julien Delange, Founder and CEO
Julien is the CEO of Codiga. Before starting Codiga, Julien was a software engineer at Twitter and Amazon Web Services.
Julien has a PhD in computer science from Universite Pierre et Marie Curie in Paris, France.
Static code analysis (or static program analysis) is the process of analyzing computer software that is mostly independent of the programming language and computing environment. It can be done without executing the program (hence the term "static" code analysis). This approach is a common method for detecting security problems and defects in programs written in any programming language. The process is often called static analysis because the program is not executed during analysis. This type of program inspection can be contrasted with dynamic analysis or testing, which involves executing a program or part of it.
Static code analysis tools power Codiga to thousands of code reviews every day. Codiga integrates many tools that support thousands of analysis rules and aggregate their results in order to provide analysis results in just a few seconds.
We want to explain the underlying technology and how static analysis works. In this blog post, we explain what is static code analysis, how it works, and what are the limitations of such an approach.
How static code analysis works?
Static Code Analysis involves two major steps:
- Transform the code into an Abstract Syntax Tree (AST)
- Apply analysis rules to find potential issues
We first explain what is an abstract syntax tree first and then, explain the process of static code analysis.
The Abstract Syntax Tree (AST)
An Abstract Syntax Tree (AST) is a way to present the structure of a programming language for use in software development. It is used to make the language easier to understand and process by a computer. It shows the structure of code, rather than the syntax or "surface form" that humans typically read. An AST also offers a way to organize programming languages into categories based on their structure.
As its name suggests, an AST uses a tree structure, where everything is a node. A node has only one parent and zero or multiple leaves. A node has a type that represents an expression or literal from the code.
For example, the following picture represents the AST of a function in C that takes two arguments (arg1 and arg2) of type int and returns void.
C code
void myfunc(int arg1, int arg2);
Corresponding Abstract Syntax Tree
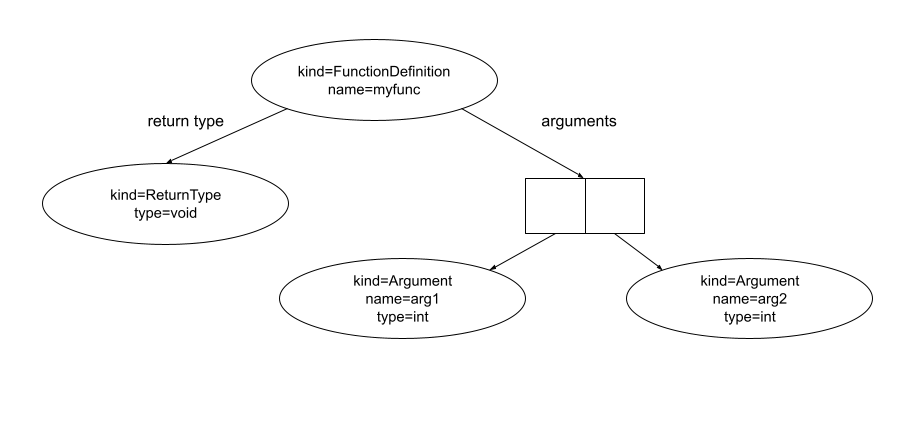
Step 1: Parsing your code and transform it into an Abstract Syntax Tree
Transforming your program into an Abstract Syntax Tree is no easy task. It starts by parsing the code, interpreting its structure, and transforming it into an AST. You can write your own parser, use an established parser, or use frameworks to generate one (such as ANTLR - the most famous parser generator).
There are challenges when parsing code. First, the code you are trying to parse may not be syntactically correct, which leads to parsing errors (and then, no AST is produced). Some parsers are resilient to parsing errors and attempt to produce an AST based on what can be parsed. Another common issue comes from a different version of a language.
As a programming language evolves (and introduces new syntax or keywords), your parser needs to evolve and handle different versions of the language. Some code can be considered as syntactically incorrect whereas it is correct and uses the latest features of a language. A good example of this is Python, when the typing module got introduced (and code with typing annotations would not be processed by parsers supporting the previous version of the language).
Step 2: Walking through the Abstract Syntax Tree
Once you have a complete AST, you can analyze it. Static Analysis Rules analyze the AST and detect potential issues in the code. The code walks through the AST and when a node of a particular type needs to be checked, the code analyzes the node leaves and checks if there is an error.
Let's take the example of a rule that analyzes Python code and checks if the get method from the requests package uses an argument timeout.
This is an example of incorrect code
requests.get(url)
This is an example of correct code
requests.get(url, timeout=2.50)
This is the AST representation of the incorrect code.
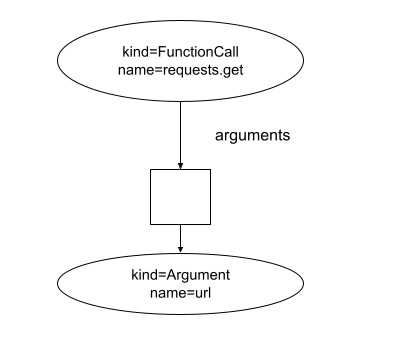
The pseudo-code of the rule that checks if the timeout argument is declared would be like this:
boolean checkNode(node) {
if (node.kind == FunctionCall && node.name == "requests.get") {
passed = false;
for(Argument argument: node.arguments) {
if (argument.name == "timeout") {
passed = true;
}
}
}
return passed;
}
Applied to the AST shown above, the rule would then return false because there is only one argument to the function call requests.get with the name url. Only the timeout argument is passed to the requests.get function call, the function checkNode would return true.
Step 3: Designing rules
Checking a large codebase and checking for many errors require writing a rule for each potential error. This is very time-consuming work. Popular static code analyzers (such as PMD, a great static code analyzer for Java) have hundreds of rules pre-configured.
Many static code analyzers (such as eslint) let users extend the tool themselves and define their own rules. They have standard interfaces developers follow to design rules. Refer to the specific static analysis tool you want to extend for these interfaces.
The Codiga Static Code Analysis engine includes thousands of static analysis rules for 12+ programming languages. You can browse these rules below.
Limitations of Static Code Analysis
Static code analysis is very powerful and flags issues in different categories (including security, safety, and performance). However, there are still many limitations.
First, writing rules is time-consuming since new rules need to be written for every potential issue for each language. Rules are also tool specific, which is very intense in terms of development.
It is also very common to have false positives (e.g. a rule flags an error when there is nothing wrong with the code). It has been one of the biggest issues with static analyzers and developers need to filter the noise in all the potential issues reported by static analysis tools. Our static analysis engine has an extra layer to filter false positives and we also allow users to disable rules for each project.
Last, static analysis tools cannot detect issues that are dependent on the runtime behavior. An issue that occurs on a specific runtime cannot be detected. Similarly, for some languages that have undefined behavior (such as C++), static analysis tools cannot diagnose precisely if a problem will occur.
Wrapping Up
Static code analyzers are very powerful tools and catch a lot of issues in source code. They help developers catch errors in their code every single day. And avoids unsafe or unsecured code from being shipped in production.
Writing a static analysis tool is a hard and time-consuming task. Developers need to write many rules to check for code correctness and such rule can still trigger false positives. Hopefully, existing static code analyzers are very extensible, and instead of writing a tool from scratch, you can add your own rules to existing tools.